Research
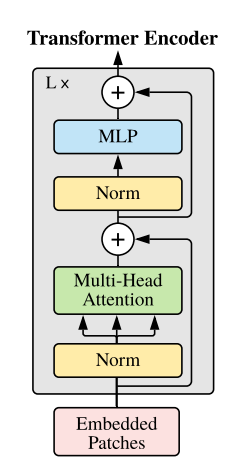
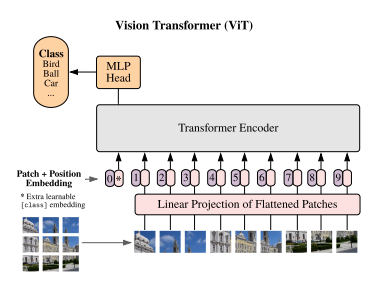
Transformerの内部構造と文の生成
Multi Head Attentionの内部処理
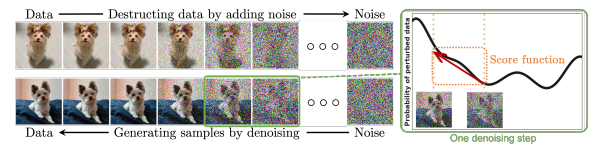
引用:https://arxiv.org/abs/2209.00796
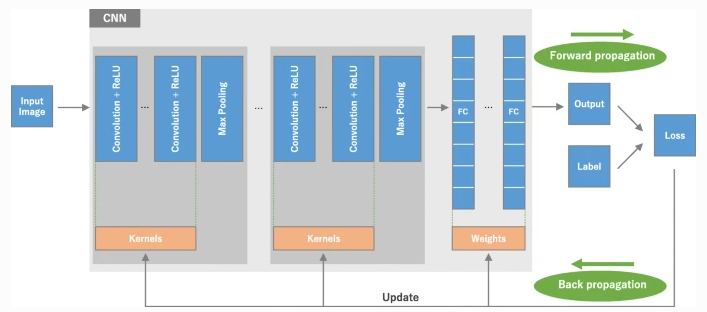
引用:https://insightsimaging.springeropen.com/articles/10.1007/s13244-018-0639-9
ご愛読ありがとうございます。