Research
Research

Transformerは2017年に発表された論文 「"Attention Is All You Need"」 に掲載されたニューラルネットワークの新しいモデルです。発表されて以来、革新的な内部機構が注目され、多くの自然言語処理タスクに利用されてきました。
近年登場したChatgptなどのLLMも、Transformerを使用した言語処理技術の一つです。さらに現在では、画像、音楽等の認識や医療分野にも使用されている優れた解析モデルです。 AIを実用化段階に躍進させたモデルであるTransformerを、その内部構造に併せて解説していきます。
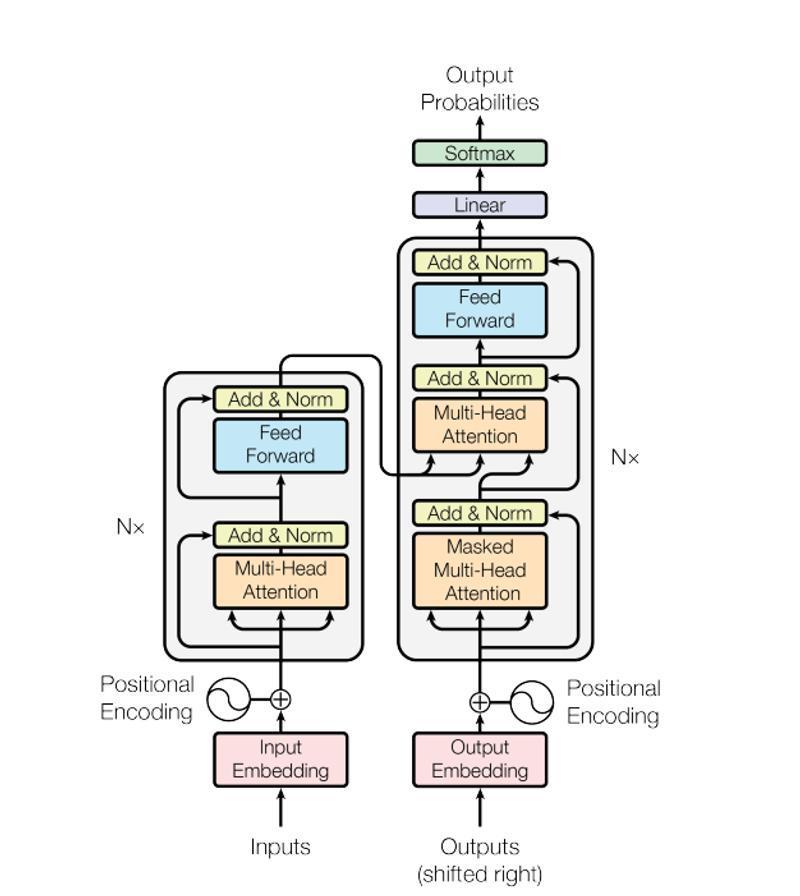
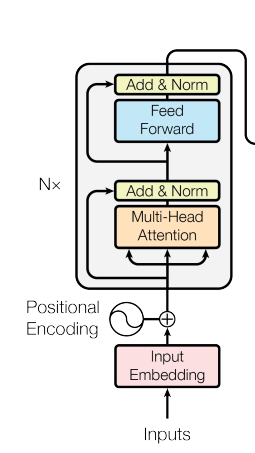
日本語から英語に翻訳する翻訳タスクにおけるTransformerのEncoderの入出力と機能について解説していきます。encoderに対する入力は、日本語の文です。 文は配列として単語ごとに分けられて入力されます。
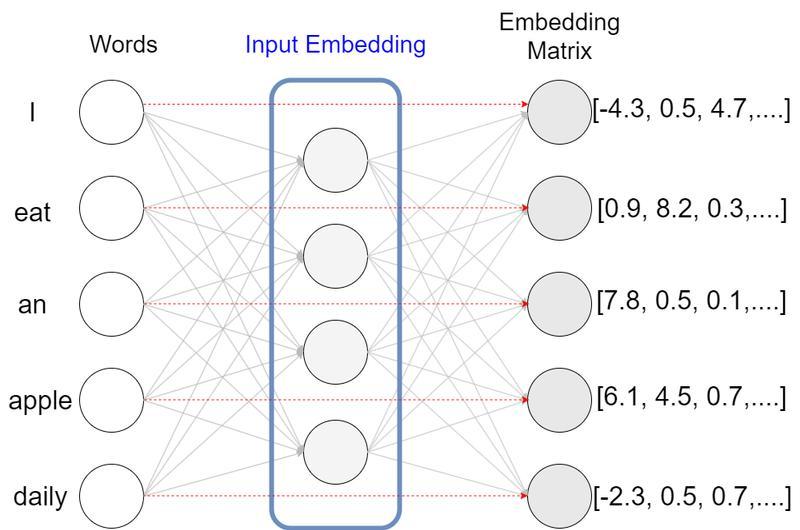
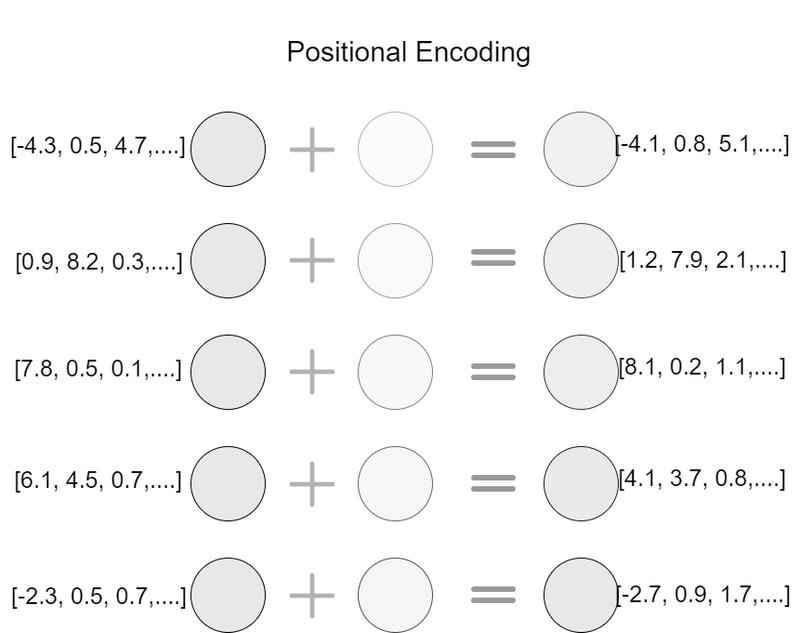
埋め込みベクトルにマッピングされた配列は、Positional Encoding処理を与えられます。後述するself attention機構では単語を並列処理するため、単語の順序関係が失われてしまいます。 Positional Encodingではsin波とcos波を使用した位置エンコーディングを埋め込みベクトルに加算することで、単語の位置関係を埋め込みベクトルに記憶させます。 これでTransformerの内部機構に渡せる形に自然言語を処理できたことになります。
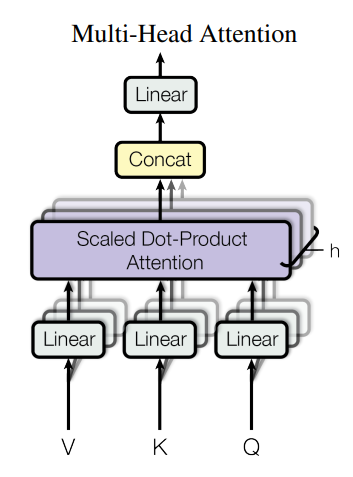
それでは内部機構の説明に移ります。内部機構ではMulti Head Attention機構を使用します。 この機構がTransformerの要となる機能ですが、詳細に解説するとかなり長くなってしまうので、ここでは簡潔にして詳細は別の記事にまとめるようにします。
Multi Head Attention機構の特徴は、入力がQuery(Q:クエリ), Key(K:キー), Value(V:バリュー)の3つに分かれていることです。 先ほどの埋め込みベクトルから、Query, Key, Valueの3値を3つの学習可能な重み行列によって作成します。
ここで、Queryは「他のどのトークンにどのくらい関連があるか」、Keyは「トークンの情報」、Valueは「MHAの最終的な出力」になります。MHAの内部ではクエリとキーを使用して最終的にValueを出力します。 Valueはその単語の情報や周辺単語との関連を数学的に示しているものだと解釈してください。
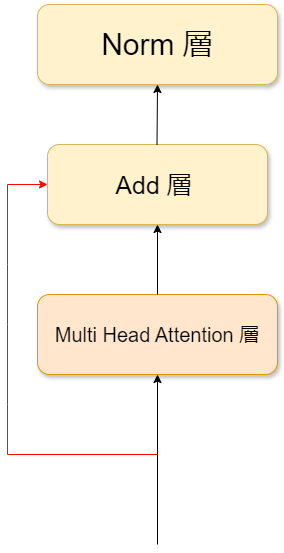
出力されたValueはAdd&Norm層に入力されます。Add層ではMHA機構の入力と出力のvalueを加算します。この操作を残差接続といいます。残差接続を行うことで、元の入力に基づいた情報を保持することが出来、 安定的に学習を進めることが出来ます。その後、Norm層を用いて配列を正規化して各ベクトルの長さが1になるようにします。正規化することで他のニューラルネットワークと同様、過学習を防ぎやすくなります。
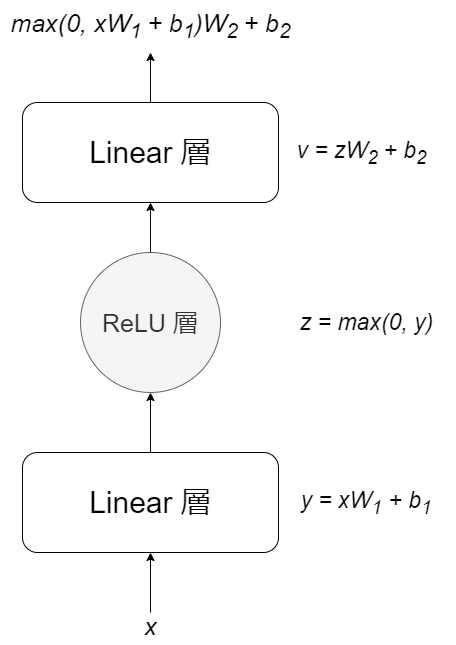
正規化されたトークンはFeed forward層で非線形変換を行います。
具体的には、重み行列とバイアスを用いて線形変換し、その後、ReLU関数を用いて非線形返還を行い、別の重み行列とバイアスを使い、 再び値を更新します。TransformerではMulti Head Attention層が注目されていますが、多くのニューロンはこのfeed forward層のMLP内部に存在します。
これはlinear層を通したあと、ReLU層を通し、再びlinear層を通すということです。重み行列とバイアスは学習を進めるごとに定義された損失関数により最適化されていきます。その後、もう一度Add&Norm層でFeed forward層の処理前と処理後を足し合わせた後正規化を行い、 正規化された出力はdecoderに渡されます。
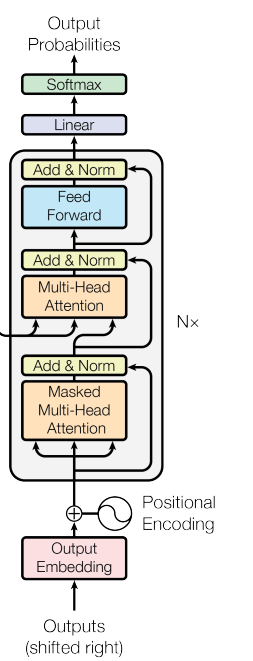
Decoderの入出力と機能を説明していきます。Decoderは最終的にEncoderに入力された文の翻訳文を出力することが求められます。しかし一度にすべての単語を翻訳するということは行いません Decoderの本質的な機能は「次の単語の予測」です。Encoderの入力は単語の行列だったのに対し、 Decoderは1単語ずつ入力していきます。<BOS>最初のステップの入力は<BOS>という特殊文字であり、この文字は文頭を表します。 <start>を入力として、Decoderは次に来る単語を予測し、出力します。出力された単語は再びDecoderに入力され、更に次に来る文字を確率的に計算します。 この繰り返しによって翻訳文を完成させます。 Decoderの内部層はEncoderとほぼ同じです。Encoderで説明した層の説明は省略します。
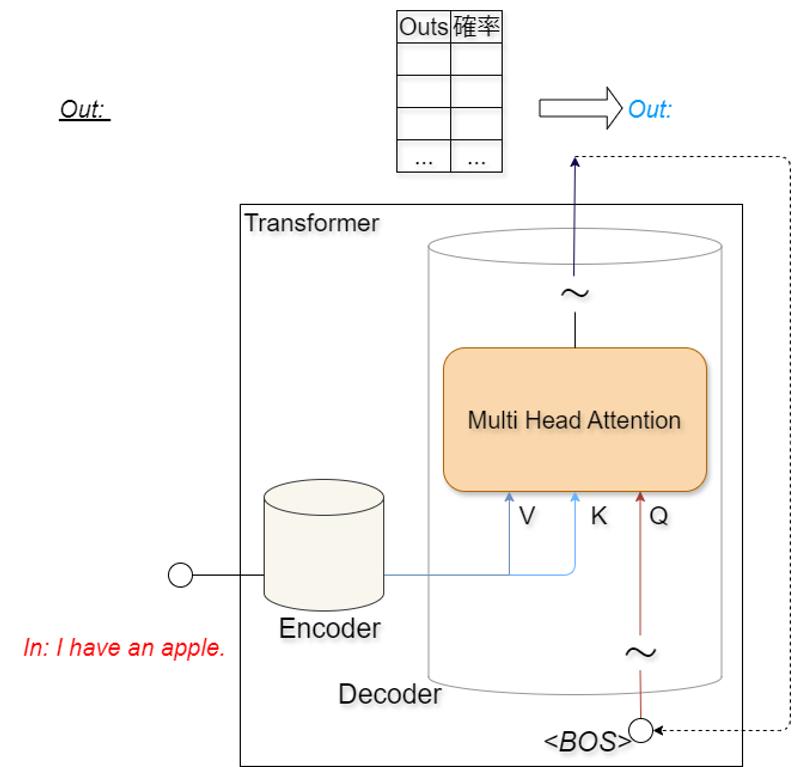
例えば、Encoderに「I have an apple」という文章を入力します。Encoderによって数値化されたデータはDecoder 内のMulti Head Attention機構のQueryとKeyとして付加されます。Decoderは付加された情報をDecoderの入力とともに処理し、<BOS>の次に来る単語を確率的に求め、最も確率の高い単語を出力します。
Masked Multi Head Attention層では未来の情報の要素を-∞と表記する(マスクする)ことで、未来の情報の要素を参照させない操作を行っています。 マスクを行うと、まだ生成されていない要素を情報量がない要素として扱うことが出来ます。 この操作も別の記事で詳しく解説します。
※埋め込み配列の要素は後の0を使って未来の情報をマスクすることはできません。
Linear層とsoftmax層は一般的に他のニューラルネットワークで使用される層と同じです。 Linear層は重み行列とバイアスを使ってベクトルを線形変換し、softmax層はベクトルから正規化された確率分布を生成します。
以上がTransformerの内部構造と学習されたTransformerがどのように出力を行うかの説明です。 各層を簡単にまとめます。
上記の層の内、デフォルトのTransformerで学習を行う層はMulti Head Attention, Linear, Feed forward層です。近年のモデルではEmbedding, Positional_Encoding層も学習を 行うことがあります。