Research
Articles
Multi Head Attention 内部処理
記事のまとめ
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax\left( \frac {QK^T}{\sqrt {d_k}} \right) V
A
tt
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
so
f
t
ma
x
(
d
k
Q
K
T
)
V
☝QとKの相関情報をVに負荷する
概要
本記事ではTransformerの内部に使用されているMulti Head Attentionの内部の層を一つずつ解説し、 なぜMulti Head Attentionが単語間の関連の理解で有用なのか説明します。
※この記事の図は2017年にGoogleにより発表された論文「
"Attention is All you need"
」内の図を引用しています。
※本記事ではMulti Head Attentionの中でも1入力からQ(クエリ), K(キー), V(バリュー)から作成するものに説明を限定してします。 一部のMulti Head AttentionではEncoderの出力をK, Vとして受け取り、Decoder内部からQを受け取っていますが、考え方は本記事の解説と同様です。
※本記事ではバッチサイズ(並列化数)を1と仮定します。
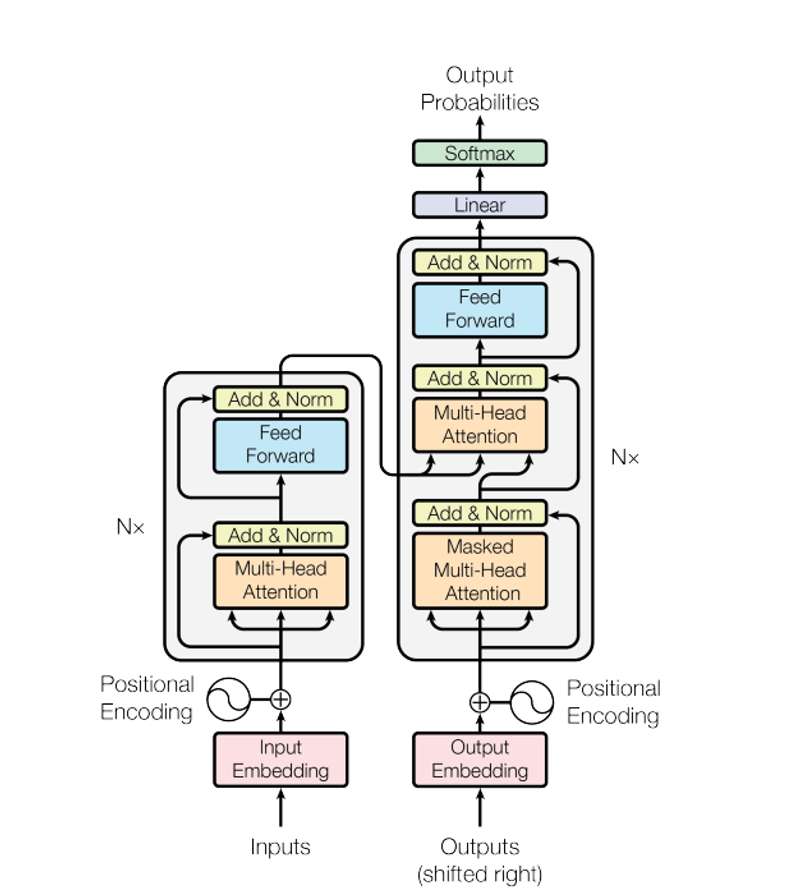
Transformer全体の内部構造や入出力に関しては以下の記事をご参照ください。
Transformerの内部構造と文の生成
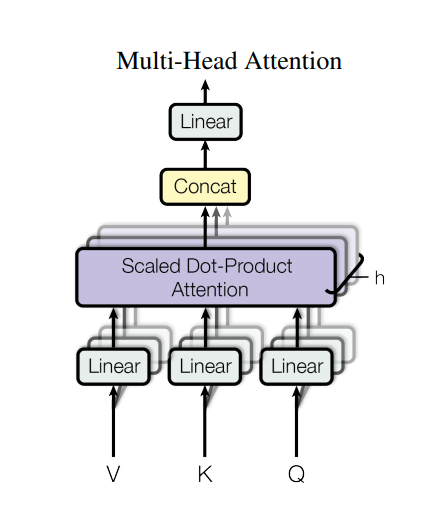
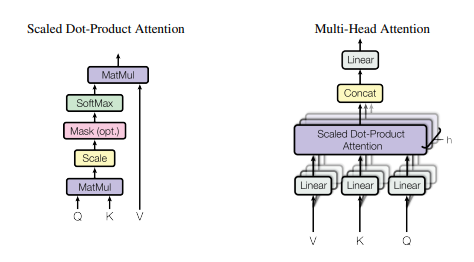
Multi Head Attentionの内部構造
Multi Head Attentionは複数(図では
h
h
h
個) のHeadと1つのConcatから構成されます。Headとは図のような, 3個のLinearと1個のScaled Dot-Product Attentionからなります。
入力Q(クエリ),K(キー),V(バリュー)はそれぞれ以下のような役割を持ちます。
Q:特定の情報を探す質問
K:質問に対する答え
V:最終的に出力する情報
Q,K,Vはモデルの構造上このような役割を持っているに過ぎず、意味などを定義しているわけではありません。 また、今回解説する1つの入力からQ,K,Vを作るような場合はQとKの役割の違いはあまり考慮しなくてもよいです。 QとKの役割の違いは特に翻訳タスクに使用されるようなEncoderを使用するモデルにおいて登場します。
Multi Head Attentionのそれぞれの層は以下のような機能を持ちます。
Linear:入力に重み行列を掛け、バイアスを足して線形変換を行う
Scaled Dot-Product Attention:Q(クエリ),K(キー),V(バリュー)を使用し、要素間の関連を計算する
Concat:複数のHead Attentionの出力を統合する
以下では各層の入出力を詳しく説明します。
L
i
n
e
a
r
Linear
L
in
e
a
r
Linear層ではQ,K,Vを作成します。 Q,K,Vは以下のような重み行列の線形変換で作られます。
Q
=
x
W
Q
Q=xW_Q
Q
=
x
W
Q
K
=
x
W
K
K=xW_K
K
=
x
W
K
V
=
x
W
V
V=xW_V
V
=
x
W
V
入力
x
x
x
はどれも同じ入力であり、
x
x
x
の行列の大きさは
n
×
d
m
o
d
e
l
n \times d_{model}
n
×
d
m
o
d
e
l
となります。
n
n
n
はトークンの要素数です。 Transformerが入力を単語ごとにトークン化するモデルなら、
n
n
n
は入力文の単語数に開始記号などを加えた数になります。
W
Q
W_Q
W
Q
と
W
K
W_K
W
K
は
d
m
o
d
e
l
×
d
k
d_{model} \times d_k
d
m
o
d
e
l
×
d
k
の行列、
W
V
W_V
W
V
は
d
m
o
d
e
l
×
d
v
d_{model} \times d_v
d
m
o
d
e
l
×
d
v
の行列です。論文「
"Attention is All you need"
」では
d
k
=
d
v
=
d
m
o
d
e
l
h
d_k=d_v=\frac {d_{model}} h
d
k
=
d
v
=
h
d
m
o
d
e
l
(
h
h
h
はHeadの数)であり 、Q,K,Vはどれも同じ大きさの行列で、大きさは
n
×
d
m
o
d
e
l
h
n \times \frac{d_{model}} h
n
×
h
d
m
o
d
e
l
です。 これらはConcatでつなぎ合わされ、
x
x
x
の元の大きさに戻ります。 headごとに重み行列が決まっており、それぞれ異なる視点で情報を判断します。
S
c
a
l
e
d
Scaled
S
c
a
l
e
d
D
o
t
−
P
r
o
d
u
c
t
Dot-Product
Do
t
−
P
ro
d
u
c
t
A
t
t
e
n
t
i
o
n
Attention
A
tt
e
n
t
i
o
n
Scaled Dot Product Attentionでは入力を
Q
,
K
,
V
Q, K ,V
Q
,
K
,
V
として出力
y
y
y
は以下の式で表されます。
y
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
y=Attention(Q,K,V)=softmax\left( \frac {QK^T}{\sqrt {d_k}} \right) V
y
=
A
tt
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
so
f
t
ma
x
(
d
k
Q
K
T
)
V
このブロックの操作は後で詳しく解説します。
C
o
n
c
a
t
Concat
C
o
n
c
a
t
Concatでは全てのheadの入力を結合して出力します。そのため、出力
y
y
y
は以下の式のようになります。
y
=
C
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
,
h
e
a
d
3
,
.
.
.
.
,
h
e
a
d
h
)
y=Concat(head_1, head_2, head_3,...., head_h)
y
=
C
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
,
h
e
a
d
3
,
....
,
h
e
a
d
h
)
Concatの出力は入力を横に結合して出力します。
[
h
e
a
d
1
h
e
a
d
2
.
.
.
h
e
a
d
h
]
\begin {bmatrix} \ head_1 & head_2 & ... & head_h \end{bmatrix}
[
h
e
a
d
1
h
e
a
d
2
...
h
e
a
d
h
]
headひとつあたりのサイズは
n
×
d
m
o
d
e
l
h
n \times \frac{d_{model}} h
n
×
h
d
m
o
d
e
l
であるため、出力
y
y
y
のサイズは
n
×
d
m
o
d
e
l
n \times d_{model}
n
×
d
m
o
d
e
l
となります。
※ただし、
d
k
≠
d
v
d_k \ne d_v
d
k
=
d
v
の場合、出力
y
y
y
のサイズは異なります。この場合は、Concatの次のLinearで出力
y
y
y
のサイズを
n
×
d
m
o
d
e
l
n \times d_{model}
n
×
d
m
o
d
e
l
にします。
以上のように、Multi Head Attentionでは入出力で行列の大きさは変わりません。
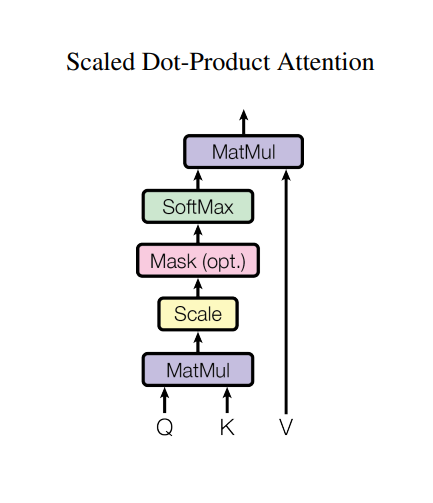
Scaled Dot-Product Attentionの構造
Scaled Dot-Product AttentionはMulti Head Attentionの中核を担うブロックで、 上図がScaled Dot-Product Attentionの図で、これを式に直すと下の式になります。
y
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
y=Attention(Q,K,V)=softmax\left( \frac {QK^T}{\sqrt {d_k}} \right) V
y
=
A
tt
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
so
f
t
ma
x
(
d
k
Q
K
T
)
V
この式がどのように単語間に関連を持たせているか、一つずつ説明していきます。
M
a
t
M
u
l
(
Q
,
K
T
)
MatMul(Q, K^T)
M
a
tM
u
l
(
Q
,
K
T
)
MatMulは行列の積を計算する演算です。
Q
Q
Q
と
K
T
K^T
K
T
の積に操作について詳しく見てみると、 以下の図のようになります。 図の表記では
Q
[
a
,
b
]
Q_{[a, b]}
Q
[
a
,
b
]
は
Q
Q
Q
の
a
a
a
行
b
b
b
列の要素を指し、
∗
*
∗
はすべての要素を指します。
M
a
t
M
u
l
(
Q
,
K
T
)
MatMul(Q, K^T)
M
a
tM
u
l
(
Q
,
K
T
)
K
[
∗
,
1
]
T
K^T_{[*, 1]}
K
[
∗
,
1
]
T
K
[
∗
,
2
]
T
K^T_{[*, 2]}
K
[
∗
,
2
]
T
...
K
[
∗
,
n
]
T
K^T_{[*, n]}
K
[
∗
,
n
]
T
Q
[
1
,
∗
]
Q_{[1, *]}
Q
[
1
,
∗
]
Q
[
1
,
∗
]
K
[
∗
,
1
]
T
Q_{[1, *]} K^T_{[*, 1]}
Q
[
1
,
∗
]
K
[
∗
,
1
]
T
Q
[
1
,
∗
]
K
[
∗
,
2
]
T
Q_{[1, *]} K^T_{[*, 2]}
Q
[
1
,
∗
]
K
[
∗
,
2
]
T
...
Q
[
1
,
∗
]
K
[
∗
,
n
]
T
Q_{[1, *]} K^T_{[*, n]}
Q
[
1
,
∗
]
K
[
∗
,
n
]
T
Q
[
2
,
∗
]
Q_{[2, *]}
Q
[
2
,
∗
]
Q
[
2
,
∗
]
K
[
∗
,
1
]
T
Q_{[2, *]} K^T_{[*, 1]}
Q
[
2
,
∗
]
K
[
∗
,
1
]
T
Q
[
2
,
∗
]
K
[
∗
,
2
]
T
Q_{[2, *]} K^T_{[*, 2]}
Q
[
2
,
∗
]
K
[
∗
,
2
]
T
...
Q
[
2
,
∗
]
K
[
∗
,
n
]
T
Q_{[2, *]} K^T_{[*, n]}
Q
[
2
,
∗
]
K
[
∗
,
n
]
T
...
...
...
...
...
Q
[
n
,
∗
]
Q_{[n, *]}
Q
[
n
,
∗
]
Q
[
n
,
∗
]
K
[
∗
,
1
]
T
Q_{[n, *]} K^T_{[*, 1]}
Q
[
n
,
∗
]
K
[
∗
,
1
]
T
Q
[
n
,
∗
]
K
[
∗
,
2
]
T
Q_{[n, *]} K^T_{[*, 2]}
Q
[
n
,
∗
]
K
[
∗
,
2
]
T
...
Q
[
n
,
∗
]
K
[
∗
,
n
]
T
Q_{[n, *]} K^T_{[*, n]}
Q
[
n
,
∗
]
K
[
∗
,
n
]
T
Q
Q
Q
は
n
×
d
k
n \times d_k
n
×
d
k
の行列であり、
K
T
K^T
K
T
は
d
k
×
n
d_k \times n
d
k
×
n
なので出力サイズは
n
×
n
n \times n
n
×
n
になります。
また、
Q
=
x
W
Q
Q=x W_Q
Q
=
x
W
Q
と
K
=
x
W
K
K=x W_K
K
=
x
W
K
から、
M
a
t
M
u
l
(
Q
,
K
T
)
=
x
W
Q
W
K
T
x
T
MatMul(Q, K^T)=x W_Q W_K^T x^T
M
a
tM
u
l
(
Q
,
K
T
)
=
x
W
Q
W
K
T
x
T
となり、本質的には
W
Q
W_Q
W
Q
の行と
W
K
W_K
W
K
の行を掛け合わせる操作になります。
行というのは各トークン(≒文中の単語)を表していますので、この演算により、重み行列
W
Q
,
W
K
W_Q, W_K
W
Q
,
W
K
の行の相関関係の大きさを表現することで、
単語間の関係を大まかに表現出来ます。
S
c
a
l
e
(
Q
K
T
)
Scale ( {QK^T} )
S
c
a
l
e
(
Q
K
T
)
M
a
t
M
u
l
MatMul
M
a
tM
u
l
で
n
×
d
k
n \times d_k
n
×
d
k
と
d
k
×
n
d_k \times n
d
k
×
n
の演算を行っていますが、これはd_Kに比例して計算量が増加し、同時に 絶対値が非常に大きな値が発生を許してしまうことになります。これでは後のsoftmax関数で正規化する際、不安定な確率分布になってしまいます。そのため、
d
k
\sqrt d_k
d
k
を使ってスケーリングします。
y
=
Q
K
T
d
k
y= \frac {QK^T} {\sqrt d_k}
y
=
d
k
Q
K
T
スケーリングに使う値としては
d
k
\sqrt d_k
d
k
が最も適切であることが分かっています。こちらは機会があれば記事にします。
M
a
s
k
Mask
M
a
s
k
DecoderのMulti Head Attentionではトークンを入力して次のトークンを予測します。この時、次のトークン以降の情報を 得られないようにするため、上三角行列を
−
∞
- \infty
−
∞
に設定します。
−
∞
- \infty
−
∞
に設定することで後のsoftmax関数で正規化した際に確率として0に表現できるようになります。 以下に4×4の例を示します。
Mask
K
[
∗
,
1
]
T
K^T_{[*, 1]}
K
[
∗
,
1
]
T
K
[
∗
,
2
]
T
K^T_{[*, 2]}
K
[
∗
,
2
]
T
K
[
∗
,
3
]
T
K^T_{[*, 3]}
K
[
∗
,
3
]
T
K
[
∗
,
4
]
T
K^T_{[*, 4]}
K
[
∗
,
4
]
T
Q
[
1
,
∗
]
Q_{[1, *]}
Q
[
1
,
∗
]
1.1
1.1
1.1
−
∞
-\infty
−
∞
−
∞
-\infty
−
∞
−
∞
-\infty
−
∞
Q
[
2
,
∗
]
Q_{[2, *]}
Q
[
2
,
∗
]
1.4
1.4
1.4
−
0.7
-0.7
−
0.7
−
∞
-\infty
−
∞
−
∞
-\infty
−
∞
Q
[
3
,
∗
]
Q_{[3, *]}
Q
[
3
,
∗
]
−
2.1
-2.1
−
2.1
1.0
1.0
1.0
0.8
0.8
0.8
−
∞
-\infty
−
∞
Q
[
4
,
∗
]
Q_{[4, *]}
Q
[
4
,
∗
]
0.9
0.9
0.9
2.9
2.9
2.9
3.3
3.3
3.3
1.4
1.4
1.4
※表中の数字はダミーです このように上三角行列をすべて
−
∞
-\infty
−
∞
にすることで、クエリは過去のキーは参照することが出来ますが、未来のキーは参照できなくなります。 この操作がどのような意味を持つのかはバリューをかける操作で分かります。
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
softmax \left( \frac {QK^T} {\sqrt d_k} \right)
so
f
t
ma
x
(
d
k
Q
K
T
)
softmaxは行列の各行の要素の値を0から1に補正し、全ての要素の和が1になるように計算します。
softmax
K
[
∗
,
1
]
T
K^T_{[*, 1]}
K
[
∗
,
1
]
T
K
[
∗
,
2
]
T
K^T_{[*, 2]}
K
[
∗
,
2
]
T
K
[
∗
,
3
]
T
K^T_{[*, 3]}
K
[
∗
,
3
]
T
K
[
∗
,
4
]
T
K^T_{[*, 4]}
K
[
∗
,
4
]
T
Q
[
1
,
∗
]
Q_{[1, *]}
Q
[
1
,
∗
]
1.00
1.00
1.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
Q
[
2
,
∗
]
Q_{[2, *]}
Q
[
2
,
∗
]
0.67
0.67
0.67
0.33
0.33
0.33
0.00
0.00
0.00
0.00
0.00
0.00
Q
[
3
,
∗
]
Q_{[3, *]}
Q
[
3
,
∗
]
0.02
0.02
0.02
0.54
0.54
0.54
0.44
0.44
0.44
0.00
0.00
0.00
Q
[
4
,
∗
]
Q_{[4, *]}
Q
[
4
,
∗
]
0.05
0.05
0.05
0.35
0.35
0.35
0.52
0.52
0.52
0.08
0.08
0.08
以上のように、確率的にクエリとキーの関係を表現することが出来ます。
M
a
t
M
u
l
(
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
,
V
)
MatMul \left( softmax \left( \frac {QK^T} {\sqrt d_k} \right) , V \right)
M
a
tM
u
l
(
so
f
t
ma
x
(
d
k
Q
K
T
)
,
V
)
最後にsoftmaxした注意量と
V
V
V
(バリュー)の行列積をとります。積を行うことで
V
V
V
に情報量を付加することが出来ます。以下に
V
V
V
の各トークンのベクトルを
V
1
,
V
2
,
V
3
,
V
4
V_1, V_2, V_3, V_4
V
1
,
V
2
,
V
3
,
V
4
とした場合の例を示します。
[
1.00
0.00
0.00
0.00
0.67
0.33
0.00
0.00
0.02
0.54
0.44
0.00
0.05
0.35
0.52
0.08
]
[
V
1
V
2
V
3
V
4
]
=
[
1.00
V
1
0.67
V
1
+
0.33
V
2
0.02
V
1
+
0.54
V
2
+
0.44
V
3
0.05
V
1
+
0.35
V
2
+
0.52
V
3
+
0.08
V
4
]
\begin{bmatrix} 1.00 & 0.00 & 0.00 & 0.00 \\ 0.67 & 0.33 & 0.00 & 0.00 \\ 0.02 & 0.54 & 0.44 & 0.00 \\ 0.05 & 0.35 & 0.52 & 0.08 \end {bmatrix} \begin{bmatrix} V_1\\V_2\\V_3\\V_4 \end{bmatrix} = \begin{bmatrix}\begin{array}{l} 1.00V_1 \\ 0.67V_1 + 0.33V_2 \\ 0.02V_1+0.54V_2+0.44V_3\\0.05V_1+0.35V_2+0.52V_3+0.08V_4 \end{array} \end {bmatrix}
1.00
0.67
0.02
0.05
0.00
0.33
0.54
0.35
0.00
0.00
0.44
0.52
0.00
0.00
0.00
0.08
V
1
V
2
V
3
V
4
=
1.00
V
1
0.67
V
1
+
0.33
V
2
0.02
V
1
+
0.54
V
2
+
0.44
V
3
0.05
V
1
+
0.35
V
2
+
0.52
V
3
+
0.08
V
4
例えば、2行目の
0.67
V
1
+
0.33
V
2
0.67V_1+ 0.33V_2
0.67
V
1
+
0.33
V
2
は、(トークン1とトークン2の相関×トークン1の情報)と(トークン2とトークン2の相関×トークン2の情報) の和となり、トークン2がどのようなトークンなのかを推測することが出来ます。 この辺りの「情報」に関する概念はTransformerの内部で処理されており、解明されていない点も多いです。
Multi Head Attentionの特徴
Multi Head Attentionの構造から発生する特徴は以下の通りです。
要素のすべてとの相関を算出する構造を持っている。
複数のheadから様々な要素、視点から相関を測ることができる。
トークンの計算を1度に行うため並列化が容易である。
まとめ
Multi Head Attentionの内部処理を順に以下にまとめます。
Linear:Q,K,Vを重み行列で作成する。
SDPA.MatMul:QとKの積を計算して相関を表現
SDPA.Scale:
d
k
\sqrt d_k
d
k
で除算して値が不安定にならないようにスケーリング
SDPA.Mask:未来の情報を参照しないように
−
∞
-\infty
−
∞
でマスク
SDPA.Softbank:確率分布に正規化
SDPA.MatMul:
V
V
V
に相関情報を付加
Concat:全てのheadの出力を繋ぐ
Linear:重み行列で線形変換(入力とサイズが違う場合は同じ出力サイズになるように補正)
ご愛読ありがとうございます。