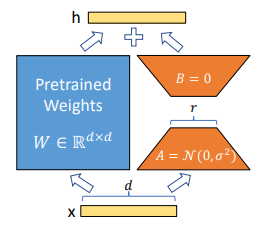
LoRAは2021年に発表された論文"LoRA: Low-Rank Adaptation of Large Language Models"引用:https://arxiv.org/abs/2106.09685
で登場した学習の軽量化手法です。一般的にLoRAは学習済みモデルに特定のタスクに特化させる学習であるファインチューニングを行う際に使用される技術になります。一般的な学習手法では重みの更新は以下の式で行われます。Wnew=Wold+δW Wnew=Wold+AB