引用:https://ja.wikipedia.org/wiki/%E6%AD%A3%E8%A6%8F%E5%88%86%E5%B8%83
made by: M.W.Toews
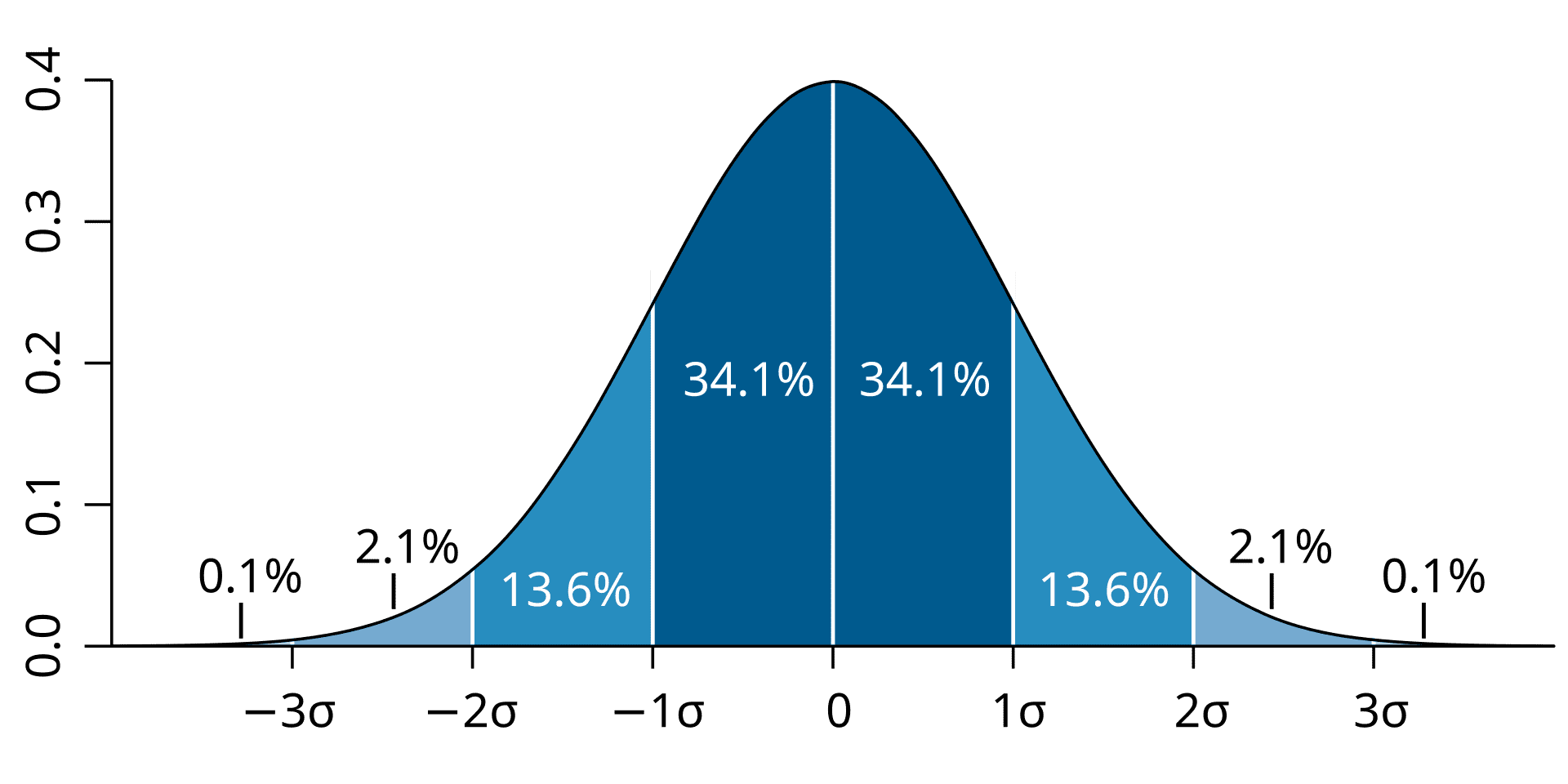
正規分布とは図のような確率分布で、以下の式で表されます。2πσ1e−21(σx−μ)2
正規分布の特徴は、次の通りです。- 平均値、中央値、最頻値が一致する
- 平均を中心として左右平均の確率分布である
- 全体面積は1である
このような特徴から、様々な事象をモデル化した分布として利用されています。
標準正規分布とは、平均μ=0かつ分散σ2=0の正規分布を指します。標準正規分布はその安定性の特徴から、多くの分野で使用されているモデルです。