Research
Research

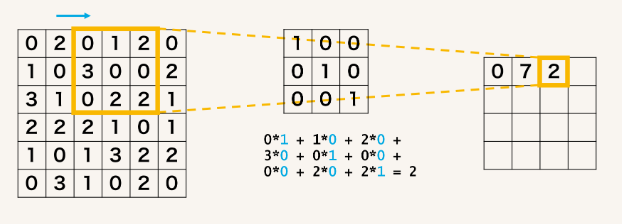
引用:https://axa.biopapyrus.jp/deep-learning/cnn/convolution.html
畳み込み演算とは、画像などの2次元データに対し、フィルタやカーネルと呼ばれる 小さな行列を用いて各位置で積和演算を実行する演算方法です。通常、フィルタを畳み込みたい行列の左上から 順にスライドしながら計算していきます。これにより、以下のような利点を得ることが出来ます。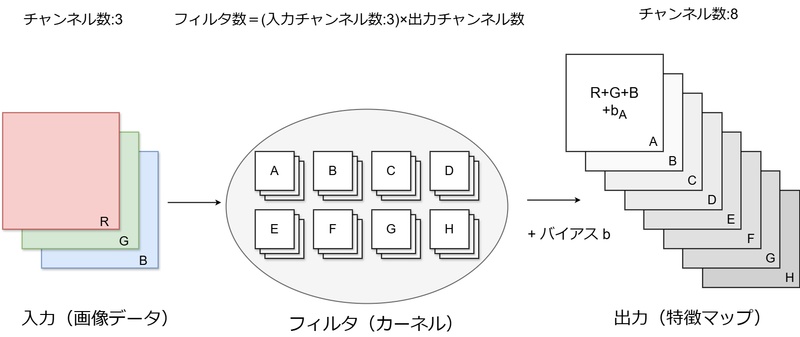
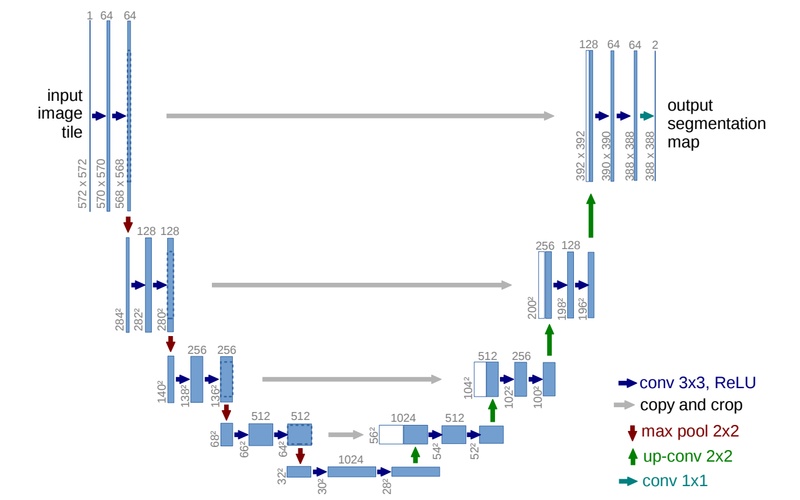
引用:https://arxiv.org/abs/1505.04597
UNetという名前は、アーキテクチャが「U」の形をしていることから名付けられました。図では、 inputのimage(画像)がoutputのsegmentation(分類)までどのように変換されているかが分かります。 一般に図の左部分、下っていく操作部をDecoder, 上っていく操作部をEncoderといいます。 図の深い場所ほど多くの畳み込みを行っているので、位置情報が薄れています。これはCNNと特徴ともいえます。 以下に図の参照方法と各矢印で表される変換がどのような操作なのかを説明します。 通常のCNNと大きく異なるのは全結合層を排除し、スキップ接続の概念を取り込んだことです。 U-Netは画像セグメンテーションに特化しており、全結合層を必要としません。その代わり、コピークロップとアップサンプリングを追加し、 スキップ接続を可能にしました。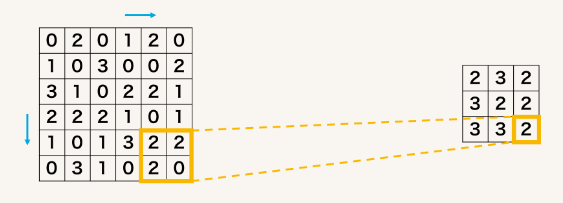
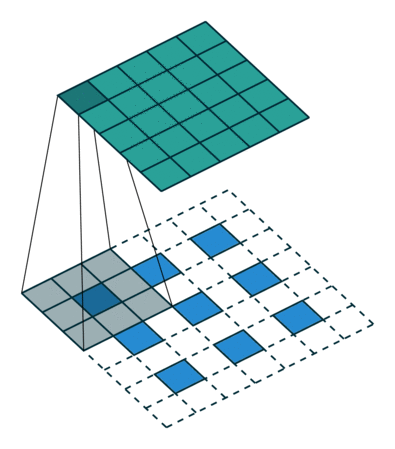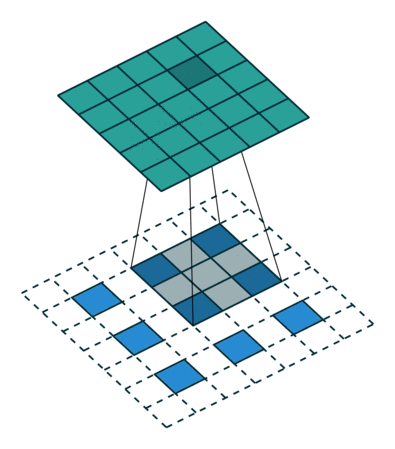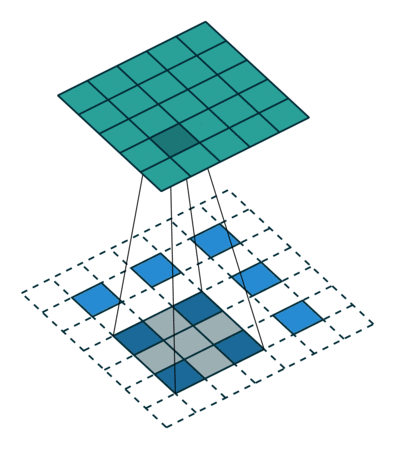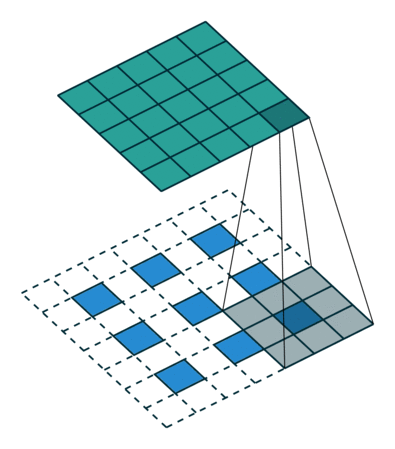
引用:https://datascience.stackexchange.com/questions/6107/what-are-deconvolutional-layers
up-convはTransposed ConvolutionまたはDeconvolution、日本語では転置畳み込みまたは逆畳み込みと呼ばれる操作で、畳み込みの逆で行列サイズを増やす操作になります。 図はTransposed Convolutionの説明に使用される有名な図です。上の緑色のマスが5×5の出力の行列、 青いマスが3×3の入力の行列であり、白いマスはすべて0です。 影になっている部分は畳み込み演算を行うウィンドウであり影になっている部分に3×3のフィルタを畳み込んで 緑色の出力を作成しています。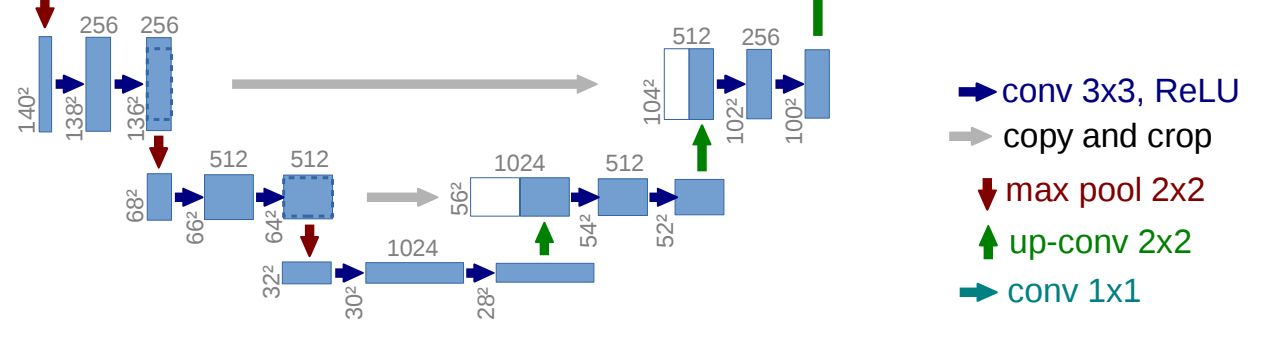
ご愛読ありがとうございます。